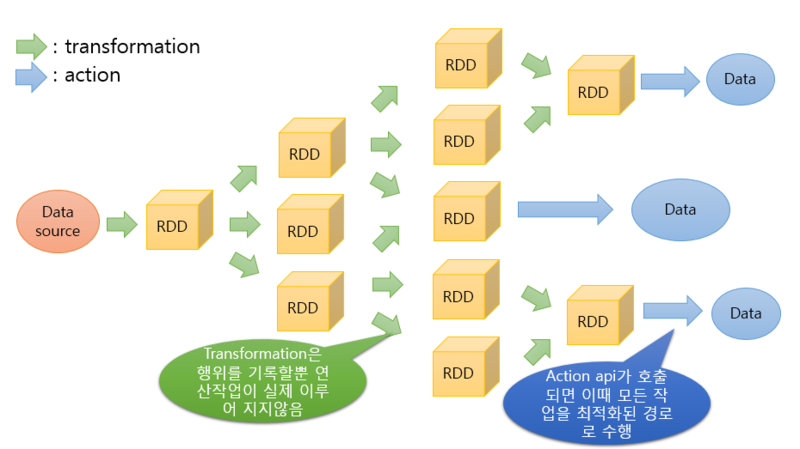
06 Spark Cluster
1. Spark Cluster 환경
- 여러 대의 서버로 구성된 환경
- 클러스터 환경에서는 여러 서버를 하나의 서버인 것처럼 다뤄야 하기 때문에 이를 도와주는 분산 작업 관리 기능이 필요
- 분산 작업 관리를 해주는 역할을 하는것을 클러스터 매니저라고 하며 Standalone, Yarn, Mesos 3가지종류의 클러스터 매니저가 있음
- 스파크에서는 클러스터 매니저를 일관되게 관리할수 있도록 추상화된 클러스터 모델을 제공
2. Spark Cluster 구조
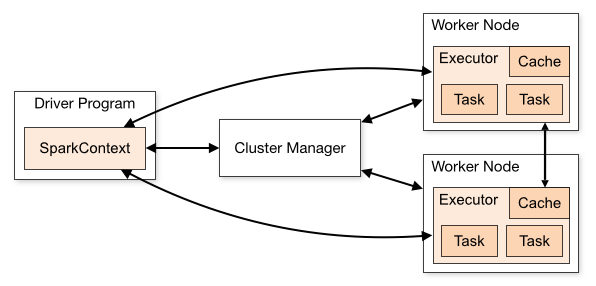
- Driver Program : 스파크 프로그램. 여러 개의 병렬적 작업으로 나눠져 Worker Node에 있는 Executor에서 실행
- SparkCotext : 메인 시작 지점. 스파크API를 활용하기 위해 필요하다. 클러스터의 연결을 보여주고 RDD를 만드는데 사용
- Cluster Manager : Standalone, YARN. Mesos 등 클러스터 자원 관리자
- Worker Node : 하드웨어 서버. 하나의 물리적 장치에 여러 개도 가능
- Executor : 프로세스. 하나의 워커 노드에 여러 개 가능
3. 클러스터 모드를 위한 일반적인 시스템 구성
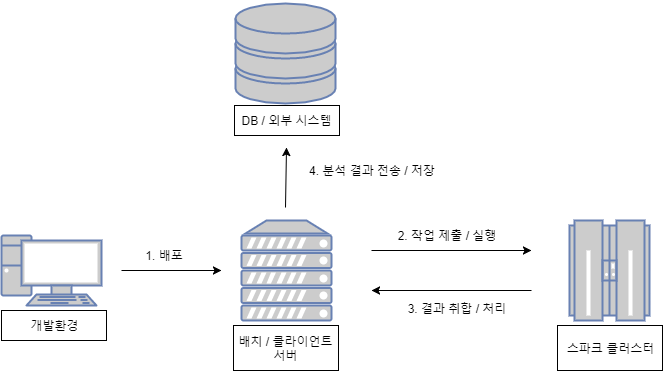
- 클러스터 모드 시스템 구성
- 로컬 개발 서버
- 개발환경을 의미
- 스파크를 설치 하지 않고 간단히 IDE상에서 라이브러리처럼 불러와서 스파크 애플리케이션을 테스트 해볼 수도 있음
- spark-submit, spark-shell등을 이용해 스파크 애플리케이션을 테스트 해봐야 하기 때문에 spark를 설치하는 편이 좋음
- 애플리케이션 실행 서버
- spark-submit, spark-shell등의 스크립트를 이용해 스파크 애플리케이션을 맨 처음 실행하는 서버
- 배치 서버라고도 불림
- 스파크, 클러스터 매니저와의 접속을 위한 환경변수나 라이브러리 필요
- 클러스터 서버
- 실제 데이터를 처리하고 필요에 따라 저장하는 워커 노드의 역할을 수행하는 서버
- 클러스터 매니저에 따라 설치해야할 프로그램이나 환경정보가 상이하다.
- 로컬 개발 서버
- 클러스터 모드 시스템 프로세스
- 배포 : 개발한 스파크 드라이버 프로그램을 배치 서버에 배포
- 작업 제출 / 실행 : 배포된 애플리케이션 수행(우지, 젠킨스)
- 결과 취합 / 처리 :
- 분석 결과 전송 / 저장 : 스프링 배치같은 별도의 애플리케이션을 통해 분석된 결과를 DB 혹은 외부시스템에 저장 및 전송
- 드라이버 프로그램과 디플로이 모드
- 클라이언트 디플로이 모드
- 애플리케이션을 실행한 프로세스 내부에서 드라이버 프로그램을 구동
- 클러스터 디플로이 모드
- 애플리케이션을 실행한 프로세스는 클로스터에게 작업 실행만 요청하고, 드라이버 프로그램은 클러스터 내부에서 구동
- 성능상의 이점이 있으나 디버깅이 어려움
- 클라이언트 디플로이 모드
4. 클러스터 매니저
4.1. Standalone
4.2. YARN
4.3. MESOS
References
- 빅데이터 분석을위한 스파크2 프로그래밍(백성민, 위키북스, 2017)