02 Scala 함수 모음
스칼라 함수 모음
- mkString() : collection을 출력하기 편하게 변환

(1 to 10 by 2).toList
class a {...}
// 클래스 선언
class MyClass private(var name: String) {
def sayHello(): Unit = {
MyClass.sayHello()
}
}
// 컴패니언 객체 선언
object MyClass {
def sayHello(): Unit = {
println("Hello" + new MyClass("sungmin").name)
}
}
// 튜플 생성
val tuple1 = (1, 2)
val tuple2 = ("a", 1, "c")
// 튜플 내용 참조
val n1 = tuple1._2
val n2 = tuple2._3
(매치할 변수) match {
case (...) => ...
case (...) => ...
}
package org.apache.spark
package object sql {
type Strategy = SparkStrategy
type DataFrame = Dataset[Row]
}
import a.b.c._
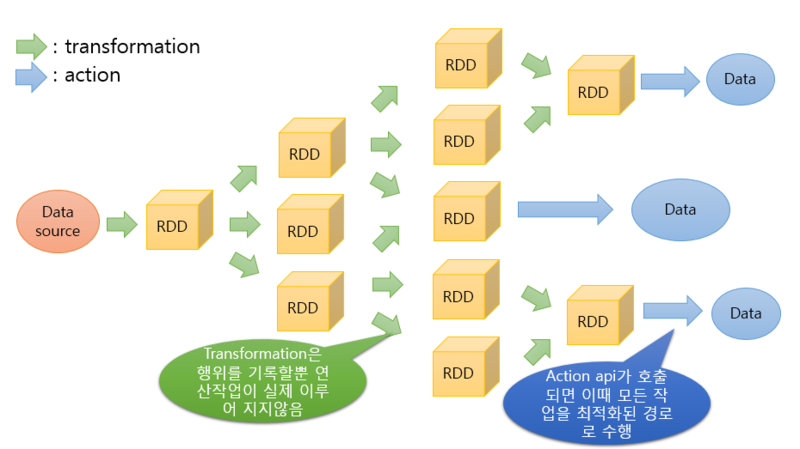
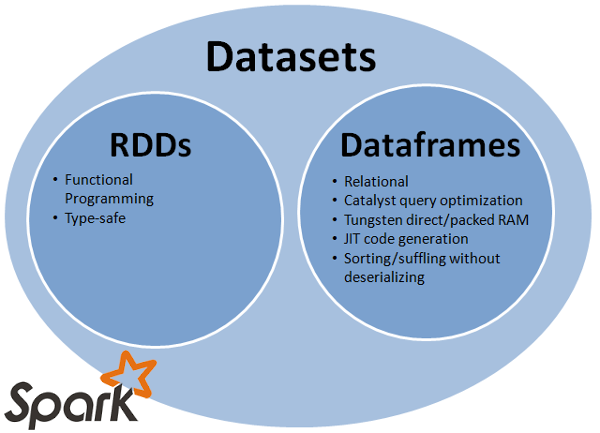
스파크 데이터 모델이란 스파크에서 데이터를 처리할때 사용하는 데이터 형식으로 Spark 초기 버전의 핵심 데이터 모델인 RDD, 이후 RDD에 스키마정보가 추가되는등 몇몇 부분이 개선된 DataFrame, RDD와 DataFrame의 장점을 취합한 DataSet까지 3가지의 데이터 모델이 존재한다.
데이터 모델 내부적으로 데이터를 변형 가공 할수있는 다양한 메소드를 API로 제공하고 있어 다루기 편리하게 설계되었다.
| 구분 | RDD | DataFrame | DataSet |
|---|---|---|---|
| 성능 | 비교적 느림 | 빠름 | 빠름 |
| 메모리 관리 | 누수 존재 | 최적화 | 최적화 |
| Type-safety | 보장 | 보장되지않음 | 보장 |
| 분석확장성 | 유연함 | 제한적 | 유연함 |