
09 Spark Data Models
1. 개요
스파크 데이터 모델이란 스파크에서 데이터를 처리할때 사용하는 데이터 형식으로 Spark 초기 버전의 핵심 데이터 모델인 RDD, 이후 RDD에 스키마정보가 추가되는등 몇몇 부분이 개선된 DataFrame, RDD와 DataFrame의 장점을 취합한 DataSet까지 3가지의 데이터 모델이 존재한다.
데이터 모델 내부적으로 데이터를 변형 가공 할수있는 다양한 메소드를 API로 제공하고 있어 다루기 편리하게 설계되었다.
2. 스파크 데이터 모델 공통 특성
2.1. Transformation API
- 데이터를 가공해서 동일한 데이터 타입으로 반환하는 연산
2.2. Action API
- 데이터를 가공해서 가공한 데이터와 다른 데이터 타입으로 반환하는 연산
2.3. 불변성
- Transformation을 수행한다고 해서 기존의 데이터가 변하는게 아니고 기존의 데이터는 남아있고 새로운 데이터를 생성
2.4. 지연 동작
- Action 연산이 호출되기 전까지 Transformation 연산은 실제로 수행되지 않음
2.5. 데이터 처리 프로세스
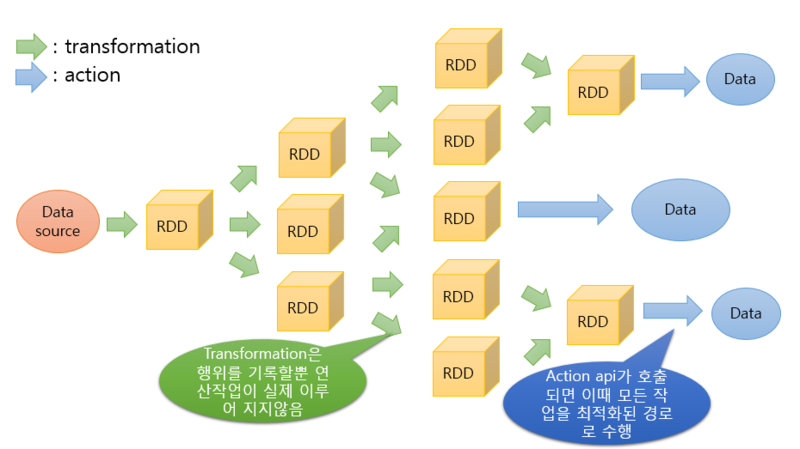
3. 스파크 데이터 모델별 비교
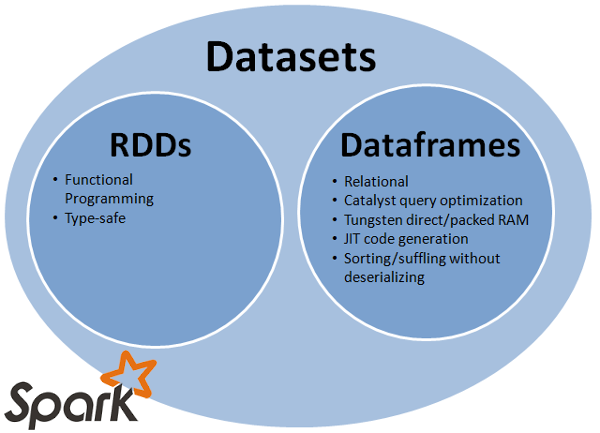
3.1. RDD
3.1.1. 특징
- Spark 0.5 부터 존재
- SparkContext로부터 생성
3.1.2. 장점
- 함수형 프로그래밍
- 타입 안전성
2.1.3. 한계
- 스키마에 대해서 표현할 방법이 없음
3.2. DataFrame
3.2.1. 특징
- Spark 1.3 부터 존재
- 현재는 2.0부터 DataSet에서 흡수, 하위 호환성을 위해 API는 남아있음
- SparkSession로부터 생성
3.2.2. 장점
- 스키마가 포함된 관계형 모델(SQL을 이용한 데이터 처리 가능)
- RDD에 비해 성능상의 이점이 있음(처리 속도, 사용 메모리)
3.2.3. 한계
- Compile Time에서 타입 안전성을 보장하지 않음
3.3. DataSet
3.3.1. 특징
- Spark 1.6 부터 존재
- DataFrame과 RDD의 장점을 모아놓은 상위호환
3.3.2. 장점
- RDD와 DataFrame이 제공하는 대부분의 기능 지원
3.3.3. 단점
- 처리해야할 작업의 특성에 따라 RDD연산에 비해 복잡한 코드를 작성해야 하는 경우가 존재
- 아직 Scala와 Java만 API 지원
3.4. 비교
| 구분 | RDD | DataFrame | DataSet |
|---|---|---|---|
| 성능 | 비교적 느림 | 빠름 | 빠름 |
| 메모리 관리 | 누수 존재 | 최적화 | 최적화 |
| Type-safety | 보장 | 보장되지않음 | 보장 |
| 분석확장성 | 유연함 | 제한적 | 유연함 |
4. 결론
- RDD, DataFrame, DataSet이 어떤 것인지에 대한 것은 알아둘 필요가 있지만 RDD와 DataFrame의 장점을 포괄하고 있는 DataSet을 사용하는 편이 좋다고 생각된다. 실제 최근에 스파크에 추가된 샘플 코드의 경우는 DataSet을 이용해 처리 하는 경우가 더 많았음
댓글