
05 Spark RDD
1. RDD에 관한 배경 지식
1.1. 스파크 클러스터
- 클러스터 : 여러대의 서버가 한대의 서버처럼 동작하는 것
- 클러스터 환경에서 동작하는 프로그램의 데이터는 여러 서버에 나눠져 병렬로 처리
1.2. 분산 데이터로서의 RDD
- RDD는 회복력을 가진 분산 데이터 집합
1.3. RDD의 불변성
- 한번 만들어진 RDD는 그 내용이 변경되지 않음
1.4. 파티션
- RDD 데이터는 클러스터를 구성하는 여러 서버에 나누어 저장
- 분할된 데이터를 파티션이라는 단위로 관리
- 파티션의 크기 조정이 애플리케이션 성능에 큰 영향을 줌
1.5. HDFS(Hadoop Distributed File System)
- 하둡의 파일 시스템
- 하둡의 파일시스템 관련 API에 대한 이해 필요
- 데이터 입출력 : InputFormat, OutputFormat
- 텍스트 파일 입출력 : SequnceFile, Parquet
1.6. Job과 Executor
- 스파크 프로그램을 실행하는 것을 스파크 잡(Job)을 실행한다고 한다.
- Job이 클러스터에서 처리될때 Executor라는 프로세스가 생성
1.7. 드라이버 프로그램
- Driver Program : Job을 실행하는 프로그램. 즉, 메인함수를 가지고 있는 프로그램
- 드라이버 프로그램은 자신을 실행한 서버에서 동작하면서 스파크 컨텍스트를 생성해 클러스터의 각 워커 노드들에게 작업을 지시하고 결과를 취합하는 역할 수행
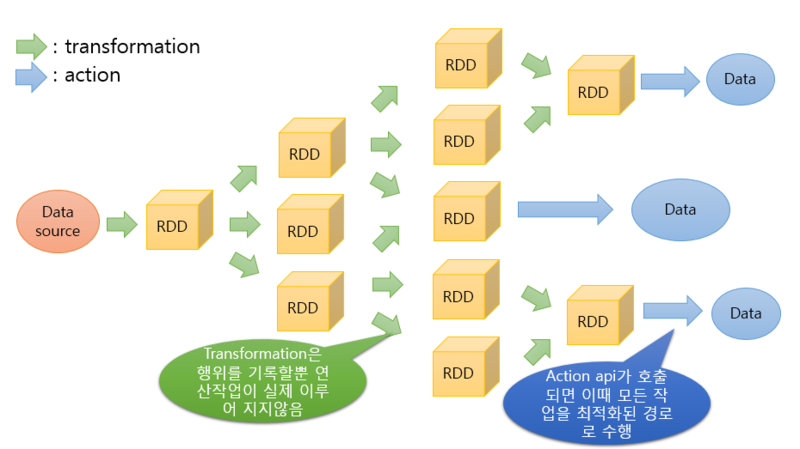
1.8. Transformation과 Action
- RDD Opertaion
- Transformation : RDD의 형태를 변형하는 연산
- Action : RDD가 아닌 다른 타입의 결과를 반환하는 연산
1.9. 지연(lazy)동작과 최적화
- 다른 Action 연산이 호출되기 전까지는 Transformation연산은 실제로 수행되지 않음
1.10. 함수의 전달
- 함수를 다른 함수의 파라미터로 전달하는 방식 사용(Javascript처럼)
1.11. 데이터 타입에 따른 RDD 연산
- PairRDDFunctions : Key-Value 구성된 테이블에 대한 연산을 제공
- OrderedRDDFunctions : Key-Value 구성된 테이블 대상으로 정렬 연산 제공
- DoubleRDDFunctions : double 타입의 데이터를 위한 것으로 sum(), mean()등의 연산 제공
- SequenceFileRDDFunctions : 하둡의 시퀀스 파일을 다루기 위한 연산 제공
- RDD Process
2. Spark Context 생성 방법
// Spark Context 설정정보
val conf = new SparkConf()
.setMaster("local[*]") // [필수]마스터 정보
.setAppName("Exam01") // [필수]애플리케이션 이름
// Spark Context 생성
val sc = new SparkContext(conf)
3. RDD 생성 방법
- 기본 RDD 생성
val rdd1 = sc.parallelize(List("a", "b","c","d","e"))
- 외부데이터를 읽어서 RDD 생성
val rdd1 = sc.textFile("<spark_home_dir>/README.md")
4. RDD Transformation
- RDD를 가공해서 RDD로 반환
- Map Operation(map 관련 연산)
- map
- 함수를 파라미터로 전달받아 내부 모든 요소에 함수를 적용 시킨 새로운 RDD 생성
- flatmap
- map과 비슷하지만 처리 결과값의 타입이 다양할 경우 지정해준 타입으로만 RDD를 생성
- mapPartitions
- RDD의 파티션 단위로 map과 같이 처리
- mapPartitionsWithIndex
- RDD의 파티션 단위로 map과 같이 처리, 파티션의 index를 파라미터로 받아서 index별로 다른 처리를 할 수 있음
- mapValues
- RDD의 요소가 Key, Value쌍으로 이루고 있을 경우 Value에 map()연산을 적용한것과 같음
- flatMapValues
- RDD의 요소가 Key, Value쌍으로 이루고 있을 경우 Value에 flatmap()연산을 적용한것과 같음
- Group Operation(그룹 관련 연산)
- RDD의 요소가 Key, Value쌍으로 이루고 있을 경우 Value에 flatmap()연산을 적용한것과 같음
- zip
- 두 개의 서로 다른 RDD를 각 요소의 인덱스에 따라 하나의 (Key, Value) 쌍으로 묶어줌
- 두 RDD는 같은 개수의 파티션, 요소의 개수를 가져야 함
- zipPartitions
- 파티션 단위로 zip()연산을 수행하고, 병합 과정에서 특정 함수를 적용해 새로운 RDD생성 가능
- 파이썬에서는 사용 불가
- groupBy
- 요소를 일정 기준에 따라 여러 개의 그룹으로 나누어진 RDD 생성
- 그룹의 Key와 그 안에 Value Sequence로 구성
- groupByKey
- 키를 기준으로 같은 Key를 가진 요소들로 그룹을 만들어 RDD 생성
- RDD의 구성요소가 Key-Value 쌍으로 이뤄진 경우 사용가능
- cogroup
- 여러 RDD에서 같은 Key를 갖는 Value 요소를 찾아와 Key와 그 Key에 속하는 Value Sequence로 구성
- RDD의 구성요소가 Key-Value 쌍으로 이뤄진 경우 사용가 능
- Set Opertaion(집합 관련 연산)
- distinct
- RDD의 요소에서 중복을 제외한 요소로만 구성된 새로운 RDD를 생성
- cartesian(곱집합)
- 두 RDD 요소의 카테시안곱을 구하고 그 결과를 요소로 하는 새로운 RDD를 생성
- [1, 2, 3] X [a, b] = [{1,a}, {1,b}, {2,a}, {2,b}, {3,a}, {3,b}]
- subtract(차집합)
- 두 RDD중 한쪽 RDD에는 속하고 다른쪽 RDD에는 속하지 않는 요소로 구성된 새로운 RDD 생성
- union(합집합)
- 두 RDD중 하나라도 속하는 요소들로 구성된 새로운 RDD 생성
- intersection(교집합)
- 두 RDD에 모두 속하는 요소들로 구성된 새로운 RDD 생성
- 중복값은 제거
- join
- RDD의 구성요소가 KV 쌍으로 구성된 경우, 두 RDD에서 서로 같은 키를 가지고 있는 요소만을 모아 그룹을 형성하는 새로운 RDD 생성
- 같은키가 없는 요소들은 제외
- leftOuterJoin, rightOuterJoin
- RDD의 구성요소가 KV 쌍으로 구성된 경우, 두 RDD에서 한쪽에 외부 조인을 수행한 결과를 새로운 RDD로 생성
- 같은키가 없는 요소들도 포함
- subtractByKey
- RDD의 구성요소가 KV 쌍으로 구성된 경우, 두 RDD에서 서로 같은 키를 가지고 있는 요소를 제외한 나머지로 구성된 새로운 RDD생성
- [HARD] Compile Opertaion(집계 관련 연산)
- RDD의 구성요소가 KV 쌍으로 구성된 경우, 두 RDD에서 서로 같은 키를 가지고 있는 요소를 제외한 나머지로 구성된 새로운 RDD생성
- reduceByKey
- RDD의 구성요소가 KV쌍으로 구성된 경우, 키를 가진 값을 하나로 병합해 KV쌍으로 구성된 새로운 RDD 생성
- foldByKey
- RDD의 구성요소가 KV쌍으로 구성된 경우, 키를 가진 값을 하나로 병합해 KV쌍으로 구성된 새로운 RDD 생성
- 병합 연산의 초기값을 메서드의 인자로 전달해서 병합 시 사용 할수 있음
- combineByKey
- RDD의 구성요소가 KV쌍으로 구성된 경우, 키를 가진 값을 하나로 병합해 KV쌍으로 구성된 새로운 RDD 생성
- 병합을 수행하는 과정에서 값의 타입이 바뀔 수 있음
- createCombiner
- mergeValue
- mergeCombiners
- aggregateByKey
- RDD의 구성요소가 KV쌍으로 구성된 경우, 키를 가진 값을 하나로 병합해 KV쌍으로 구성된 새로운 RDD 생성
- Pipe & Partition Operation
- pipe
- 데이터 처리 과정에서 외부 프로세스 활용 가능
- coalesce
- RDD의 파티션 개수를 줄일때, 성능이 repartition보다 좋음
- repartition
- RDD의 파티션 개수를 조정할때, 성능이 coalesce보다 나쁨
- repartitionAndSortWithinPartitions
- 데이터를 특정 기준에 따라 여러 개의 파티션으로 분리하고 각 파티션 단위로 정렬을 수행한 뒤 이결과로 새로운 RDD를 생성해 주는 메서드
- partitionBy
- KV쌍으로 구성된 RDD를 해당 인스턴스 인자에 따라 파티션으로 나누어진 RDD 생성
- HashPartitioner
- RangePartitioner
- pipe
- Filter & Sort Opertaion
- filter
- 원하는 요소만 걸러내는 메소드
- sortByKey
- Key값을 기준으로 정렬하는 메소드
- keys
- RDD에서 Key값을 요소로 하는 RDD를 만드는 메소드
- values
- RDD에서 Value값을 요소로 하는 RDD를 만드는 메소드
- sample
- RDD에서 샘플을 추출하게 해주는 메소드
- withReplacement : 복원/비복원 추출 여부
- fraction :
- seed : 반복 시행시 일정한 결과값을 나오도록 제어하는 인자
- filter
5. RDD Action
- RDD를 가공해서 RDD가 아닌 다른 값을 반환
- lazy evaluation
- RDD에 Action을 할때 Transform도 한꺼번에 발생하기 때문에, 반복되는 Action의 경우 성능향상을 위해 적절한 Caching이 필요
- 출력과 관련된 연산
- first
- RDD의 첫번째 요소 하나 반환
- take
- RDD의 첫번째 요소로부터 매개변수 개수 만큼 collection(Array, List)으로 반환
- takeSample
- RDD에서 지정된 크기의 샘플을 추출
- sample과는 달리 샘플의 크기를 지정할 수 있고, 반환 타입이 컬렉션 타입
- collect
- RDD의 모든 요소를 컬렉션 타입으로 반환
- 메모리를 많이 사용하기 때문에 적당한 크기의 RDD를 대상으로만 사용해야 함
- count
- RDD에 있는 모든 요소의 개수를 반환
- countByValue
- RDD에 속하는 각 Value값들이 나타나는 횟수를 구해서 맵 형태로 반환
- reduce
- RDD에 포함된 임의값 두개를 하나로 합치는 함수를 인자로 받아서 RDD에 포함된 모든 요소를 하나의 값으로 병합하고 그 결과값을 반환
- reduceByKey
- reduce와 비슷하지만 합산이 key별로 진행됨
- fold
- RDD 내의 모든 요소를 대상으로 교환법칙과 결합법칙이 성립되는 바이너리 함수를 순차 적용해 최종 결과를 구하는 메서드
- reduce와 비슷하지만 병합연산의 초기값을 지정해 줄 수 있다.
- aggregate
- 타입 제약 사항떄문에 입력과 출력의 타입이 다른경우
- 인자 : zeroValue(기본값), seqOp(함수), combOp(함수)
- sum
- RDD 내의 모든 요소가 숫자 타입일 경우에만 사용 가능하며 전체 요소의 합을 구해줌
- foreach
- RDD의 모든 요소에 특정 함수를 적용하는 메서드
- foreachPartition
- foreach를 파티션 단위로 적용
- toDebugString
- RDD의 세부정보를 알고 싶을때 사용
- RDD의 파티션 개수, 의존성 정보등을 알 수 있음
- cache
- 반복되는 RDD 트랜스포메이션 연산이 비효율 적일때, 트랜스포메이션한 RDD를 메모리에 저장하여 사용 하게 해주는 메서드
- 메모리가 부족하면 가용 메모리 만큼만 저장
- persist
- cache와 비슷하지만 StorageLevel이라는 옵션을 이용해 저장 위치(메모리, 디스크), 저장 방식(직렬화 여부) 지정 가능
- 저장위치를 MEMORY_AND_DISK_SER로 설정하면 메모리에 저장하다가 부족하면 DISK를 사용하되 직렬화된 포맷을 이용해 저장
- unpersist
- 저장중인 데이터가 필요 없을때 캐시 설정을 취소하는 메서드
- partitions
- RDD의 파티션 정보가 담긴 배열을 반환
- getNumPartitions
- RDD의 파티션 수를 반환
6. RDD 데이터 불러오기, 저장하기
- 파일 : 텍스트, JSON, 하둡의 시퀀스파일, csv
- 파일시스템 : 로컬 파일시스템, HDFS, AWS S3, 오픈스택의 Swift
- RDBMS : MySQL
- NoSQL : HBase, 카산드라, Hive
- 경로는 모든 클러스터에서 동일하게 접근이 가능해야 한다.
- RDD는 Data Set혹은 Data Frame과는 달리 데이터를 저장할 때 기존에 생성되있는 파일이 존재하면 오류를 발생시킨다.
- 텍스트 파일(Text File)
- textFile : 불러오기
- saveAsTextFile : 저장하기
- 저장할때 압축 코덱을 사용할거면 두번째 인자로 압축코덱의 클래스 경로를 넣으면 됨
- 오브젝트 파일(Object File)
- objectFile : 불러오기
- saveAsObjectFile : 저장하기
- 시퀀스 파일(Sequence File)
- sequenceFile : 불러오기
- saveAsSequenceFile : 저장하기
7. 클러스터 공유변수
- 브로드캐스트 변수(Broadcast Variables)
- 스파크 잡이 실행되는 동안 클러스터 내의 모든 서버에서 공유할 수 있는 읽기전용 자원을 설정할 수 있는 변수
- 브로드캐스트 변수 설정 방법
- 공유하고자 하는 데이터를 포함한 오브젝트 생성
- 생성된 오브젝트를 broadcast() 메서드의 인자로 지정해 실행
- 생성된 broadcast 변수는 value() 메서드를 통해 접근 가능
val broadcastUsers = sc.broadcast(Set("u1", "u2")) val rdd = sc.parallelize(List("u1", "u3", "u3", "u4", "u5", "u6"), 3) val result = rdd.filter(broadcastUsers.value.contains(_)) - 동일한 스테이지 내에서 실행되는 테스크 간에는 동작에 필요한 변수를 자동으로 브로드캐스트 변수를 이용해 전달
- 어큐뮬레이터(Accumulators)
- 브로드캐스트 변수와는 반대로 Accumulator는 쓰기 동작을 위한 것
- 주로 에러 정보같은 로그를 한곳에 모아서 디버깅 하기 위해 사용
- 기본 제공 Accumulator 종류
- longAccumulator
- DoubleAccumulator
- CollectionAccumulator
- Accumulator 사용 방법
val acc1 = sc.longAccumlatior("invalidFormat") val acc2 = sc.collectionAccumlator[String]("invalidFormat2") va data = List("U1:Addr1", "U2:Addr2", "U3", "U4:Addr4", "U5;Addr5", "U6:Addr6", "U7::Addr7") sc.parallelize(data, 3).foreach { v => if (v.split(":").length != 2) { acc1.add(1L) acc2.add(v) } } println("잘못된 데이터 수 : " + acc1.value) println("잘못된 데이터 : " + acc2.value)- 사용자 정의 Accumulator ```scala import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.util.AccumulatorV2
class RecordAccumulator extends AccumulatorV2[Record, Long] {
private var _record = Record(0)
// 초깃값 여부
def isZero: Boolean = _record.amount == 0 && _record.number == 1// 동일한 값을 가진 새로운 어큐뮬레이터 생성 def copy(): AccumulatorV2[Record, Long] = { val newAcc = new RecordAccumulator newAcc._record = Record(_record.amount, _record.number) newAcc }
// 어큐뮬레이터에 포함된 데이터의 값을 초기화 def reset(): Unit = { _record.amount = 0L _record.number = 1L }
// 다른 데이터 병합 def add(other: Record): Unit = { _record.add(other) }
// 다른 어큐뮬레이터 병합 def merge(other: AccumulatorV2[Record, Long]): Unit = other match { case o: RecordAccumulator => _record.add(o._record); case _ => throw new RuntimeException }
// 최종 결과(AccumulatorV2의 출력 타입과 같아야 함) def value: Long = { _record.amount } } ```
댓글