
01 Spark 개관
1. Spark란
- 범용적 목적의 고성능 대용량 클러스터링 분산 처리 분석 플랫폼
2. 빅데이터 솔루션에서 필요한 모듈
- 데이터 수집 모듈 : 여기저기 다양한 형태로 흩어진 데이터를 수집해서 그다음 단계에 있는 모듈에게 전달해주는 역할
- Flume, Kafka, SQOOP, Fluentd
- 데이터 저장 및 조회 모듈 : 수집된 데이터에 대한 CRUD과정을 수행하는 모듈
- Hadoop, HBase, Cassandra, Redis, Pig, Hive
- 데이터 분석 및 가공 모듈 : 데이터를 분석, 가공할수 있으며 그 결과를 외부 시스템에 전달 할 수 있는 모듈
- R, Cloudera, Hortonworks, Mahout
- 워크플로우 엔진 : 다양한 빅데이터 관련 소프트웨어들을 통일된 방식으로 제어하는 모듈
3. Spark의 특징
- 플랫폼으로써의 특성(Hadoop Map&Reduce + Apache Storm + Hadoop Hive + Apache Mahout)
- 기존에는 데이터 정제 및 가공을 하기 위해서 Map&Reduce를 사용하고, sql을 사용하기 위해서는 hive를 사용하는 등 다양한 플랫폼을 도입해야 했었지만 Spark 하나의 시스템만을 설치해도 batch, streaming, graph processing, sql 등의 처리가 가능
- 기존의 Workflow
- 데이터 수집 -> 데이터 저장(HDFS) -> 데이터 정제 및 처리(Map&Reduce, HIVE) -> 데이터 분석 및 시각화(Mahout, R)
- Spark를 이용한 Workflow
- 데이터 수집 -> 데이터 저장(HDFS) -> 데이터 정제, 처리, 요약데이터, 시각화, 분석(Spark)
- 빠른속도 : 파일 시스템 기반으로 처리하는 Hadoop의 Map&Reduce와 달리 메모리 기반 데이터 처리방식이어서 빠를수 밖에 없음
- 다양한 언어 지원(스파크 구현 자체는 Scala, API 지원은 Scala, Java, Python, R)
4. Spark Stack 구조
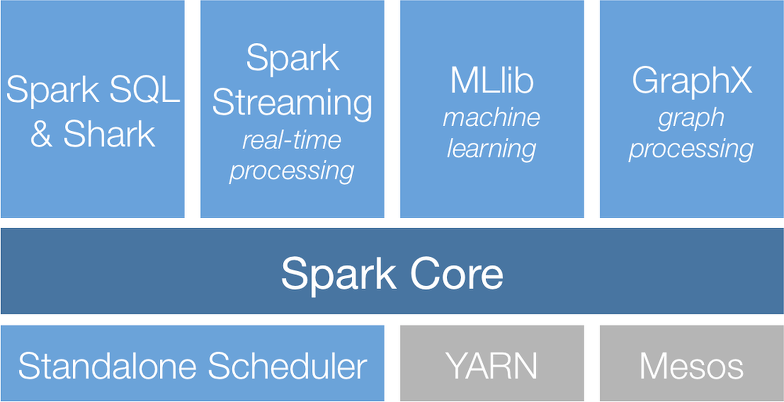
- 인프라 계층 : 먼저 스파크가 기동하기 위한 인프라는 Spark 가 독립적으로 기동할 수 있는 Standalone Scheudler가 있고 (그냥 스팍만 OS위에 깔아서 사용한다고 보면 됨) 또는 하둡 종합 플랫폼인 YARN 위에서 기동될 수 있고 또는 Docker 가상화 플랫폼인 Mesos 위에서 기동될 수 있다.
- Spark Core : 메모리 기반의 분산 클러스터 컴퓨팅 환경인 Spark 코어가 그 위에 올라간다.
- Built-in Library
- SparkSQL : 빅데이타를 SQL로 핸들링
- Spark Streaming : 실시간으로 들어오는 데이타에 대한 리얼타임 스트리밍 처리
- MLib (machine learning) : 머신러닝
- GraphX (graph) : 그래프 데이타 프로세싱
5. Spark Cluster 구조
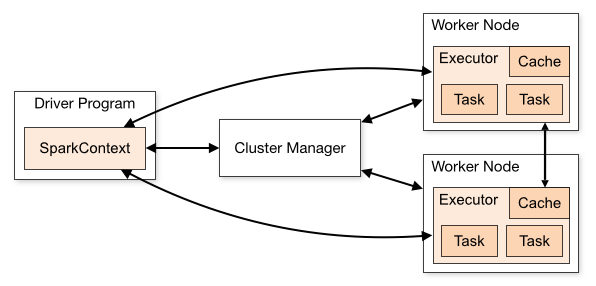
- Driver Program : 스파크 프로그램. 여러 개의 병렬적 작업으로 나눠져 Worker Node에 있는 Executor에서 실행
- SparkCotext : 메인 시작 지점. 스파크API를 활용하기 위해 필요하다. 클러스터의 연결을 보여주고 RDD를 만드는데 사용
- Cluster Manager : Standalone, YARN. Mesos 등 클러스터 자원 관리자
- Worker Node : 하드웨어 서버. 하나의 물리적 장치에 여러 개도 가능
- Executor : 프로세스. 하나의 워커 노드에 여러 개 가능
6. Spark application 실행 과정
Spark application : 클러스터에서 독립된 프로세스들의 묶음으로 동작하며, 메인 프로그램(driver Program)의 SparkContext object에 의해서 조정된다.
- Driver Program(프로세스)가 main을 실행시키며 SparkContext 생성한다.
- SparkContext가 Cluster Manager에 연결된다.
- 연결되면, 클러스터 내의 Executor를 할당받는다.
- SparkContext가 application code(SparkContext에 전달된 Jar 또는 Python file)를 executor에 보낸다.
- SparkContext가 실행할 task를 executor에 보낸다.
7. RDD(Resilent Distributed Dataset)
- RDD란 스파크가 사용하는 핵심 데이터 모델로서 다수의 서버에 걸쳐 분산 방식으로 저장된 데이터 요소들의 집합을 의미하며, 병렬처리가 가능하고 장애가 발생할 경우에도 스스로 복구될 수 있는 내성을 가지고 있다.
- 즉, RDD란 스파크에서 정의한 분산 데이터 모델인데 내부에는 단위 데이터를 포함하고 있고, 저장할때는 여러 서버에 나누어 저장되며, 처리할 떄는 각 서버에 저장된 데이터를 동시에 병렬로 처리할 수 있다는 의미
8. 개발 언어 선택
- Java, Scala, Python, R을 통해 개발 가능
- 스파크2.0버전부터 프로그래밍 언어의 종류와 무관한 API의 성능을 제공하도록 개선됨
- 하지만 문법의 간결함과 사용하기 편리한 API를 제공한다는 이유로 Scala를 1순위 개발언어로 추천하는 편임
- 스파크가 Scala로 작성되었기 때문에 Scala를 모르면, 스파크 내부 코드를 수정하거나 이해하기는 힘들다는 점이 있음
9. 실제 구동 방법
- Run-example : 스파크에 포함된 예제 소스를 구동해 볼 수 있음
- ALS 예제(스파크 홈 경로에서)
- 실행 : ./bin/run-example ml.ALSExample
- 설명 : movielens 샘플 데이터(data/mllib/als/sample_movielens_ratings.txt)를 활용한 영화추천예제 소스를 실제 구동시켜 볼 수 있음
- ALS 예제(스파크 홈 경로에서)
- Spark-shell : Spark에서 지원하는 셸에서 직접 코드를 작성(PERL)해 구동해 볼 수 있음
- Spark-submit : 실제 구현한 코드를 빌드한 뒤 구동해 볼 수 있음
10. 관련 Framework
- 웹기반 노트북, 시각화툴 : Apache Zeppelin
댓글